
If you have done your homework and read the Confluent blog, you probably have seen this great deep-dive into Connect error handling and Dead Letter Queues post.
Robin Moffatt does a great job explaining how Kafka Connect manages error based on connectors configuration, including sending failed records to DLQs for Sink connectors. The blog post also introduces the concept of “Error tolerance” as something that can be configured per connector and Connect will honor:
We’ve seen how setting errors.tolerance = all will enable Kafka Connect to just ignore bad messages. When it does, by default it won’t log the fact that messages are being dropped. If you do set errors.tolerance = all, make sure you’ve carefully thought through if and how you want to know about message failures that do occur. In practice that means monitoring/alerting based on available metrics, and/or logging the message failures.
The Apache Kafka Documentation describes errors.tolerance in simple terms.
Behavior for tolerating errors during connector operation. ‘none’ is the default value and signals that any error will result in an immediate connector task failure; ‘all’ changes the behavior to skip over problematic records.
Despite the succinct description, there are two interesting points in it:
- What errors will be skipped if we choose
all? - What does it mean problematic records?
Not all errors are born equal
If we look into the Kafka codebase, we quickly find that the logic for this error control with tolerance is centralized in one class: RetryWithToleranceOperator.
There we can find this interesting fragment:
static {
TOLERABLE_EXCEPTIONS.put(Stage.TRANSFORMATION, Exception.class);
TOLERABLE_EXCEPTIONS.put(Stage.HEADER_CONVERTER, Exception.class);
TOLERABLE_EXCEPTIONS.put(Stage.KEY_CONVERTER, Exception.class);
TOLERABLE_EXCEPTIONS.put(Stage.VALUE_CONVERTER, Exception.class);
}This static initialization controls what errors are considered tolerable, depending on when they occur. At the moment, errors are only tolerated when they happen in the key/value/header converter or during source/sink record transformation.
However, the Exception class does not represent all possible Java errors. Looking at the Java exception class hierarchy, we see other errors could escape this control mechanism.
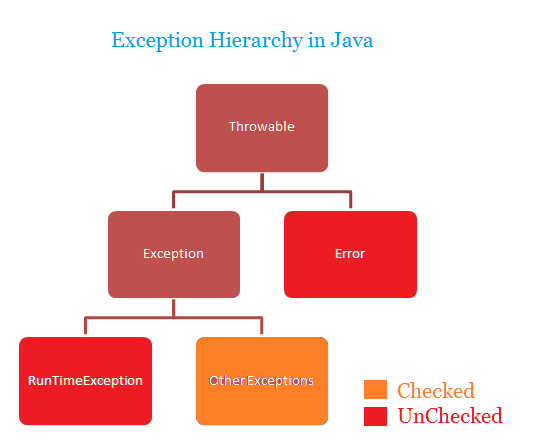
That is expected, though. Reading the Javadoc for Error, this is the first paragraph:
An
Erroris a subclass ofThrowablethat indicates serious problems that a reasonable application should not try to catch. Most such errors are abnormal conditions.
Kudos to Kafka Connect for acting as a reasonable application and catching the right base exception 🙂
When is a record problematic?
Now that we know what errors are tolerated, when configured so, let’s dig a bit into what a “problematic record” represents.
As mentioned in the section above, the error tolerance mechanism is only applied during key/value/header converter and source/sink record transformation. However, there is much more to the lifecycle of a source/sink record than those steps. Once again, the Connect codebase reveals all the steps, codified in the Stage enum.
For a source task (one that takes information from a non-Kafka system and publishes it to Kafka), these are the steps:

Equally, for a sink task (takes records from Kafka and send them to a non-Kafka system), the steps are:

If we scrutinize these two diagrams, we will notice that the error control that Connect offers us is centered around the records manipulation. In other words, the steps that are wrapped by the RetryWithToleranceOperator class should perform almost entirely deterministic operations that are exempt from the perils of distributed systems. That is not true for the AvroConverter, which registers schemas with Schema Registry. However, that is a relatively straightforward interaction compared to the complexity that Kafka Producers and Consumers deal with, not to mention the bigger unknowns happening in the many Source and Sink Connector plugins that Kafka Connect support.
In a nutshell, a problematic error is one that fails by its data. There is another name for this pattern: poison pills
Conclusion
The error mechanism in Kafka Connect is focused on managing gracefully problematic records (a.k.a., poison pills) that cause all sorts of Exception errors. Anything else outside of this scope (e.g., issues when consuming or producing Kafka records) cannot be controlled by the user through the Connector configuration, as of today.
In a subsequent post, we will zoom into those other stages in the source and sink task pipelines that aren’t controlled by configuration. That is important to understand how a Kafka Connect connector can fail, independently of what connector plugin we are using.

Excellent explanation
Aconsejas implementar confluent schema registry en un entorno productivo con un gran volumen de datos? El control de error tolerance es bastante sencillo de implementar, comparado con la gestión de schema registry