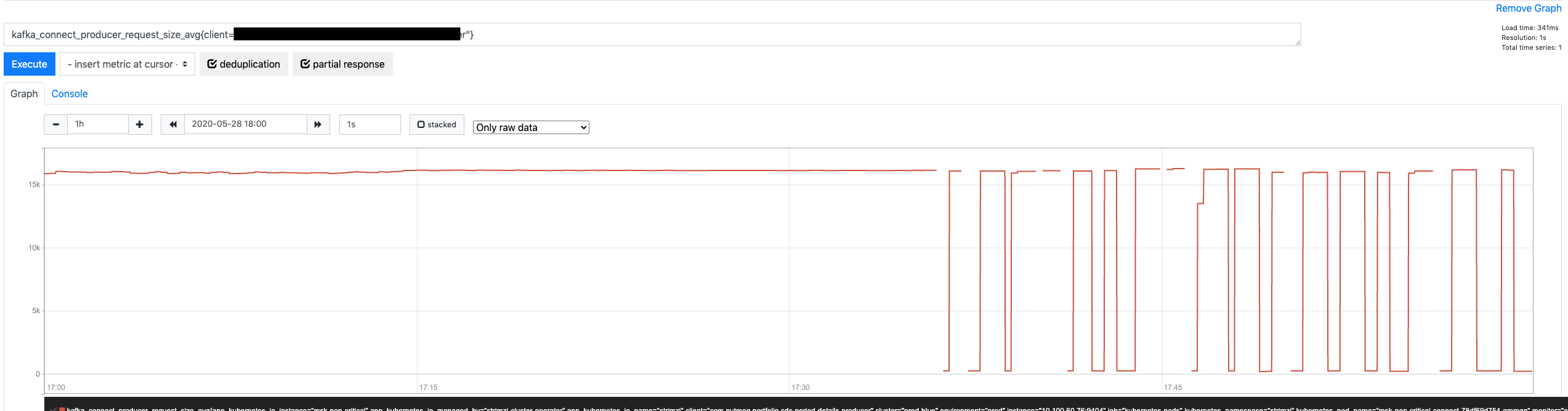
In the last post, we examined the problem in detail, established a hypothesis about the issue, and validated it with multiple metrics that pointed in the expected direction.
However, I intentionally left out any suggestion for a solution, although the investigation would have given us some hints on what we can do. In this post, we look at possible solutions and the pros/cons of each one.
Controlling the flow at Debezium
As discussed in the previous post, Debezium has a number of configuration settings that influence how the Connector pre-fetches MySQL data changes and convert them into SourceRecord objects and how they are delivered to Kafka Connect when it calls poll on the connector:
| Setting | Default | Description |
|---|---|---|
max.queue.size | 8192 | Max number of pre-fetched records, awaiting to be polled by Connect |
max.batch.size | 2048 | Max number of records delivered in every call to poll |
On the pro side, it is easy to imagine that if we restricted these two values, it would be possible to reduce the amount of data that flows from Debezium to Connect. However, on the cons side, it would be tough to configure them in a way that produces a deterministic reduction of the number of outstanding messages.
Bear in mind that, as we saw in the last post, Connect constantly calls poll, even before the previous batch of records has been acknowledged. Therefore, I expect that if we were to reduce max.batch.size to 1024, the only result we would obtain is more calls to poll from Connect while still filling the outstanding messages queue.
Think about the flow:
pollreturns 1024 records.- Connect
puts these records in the outstanding message queue. - Connect
sends these records with theKafkaProducer. KafkaProducerputs those records in its internal queue immediately.- Connect finishes the loop and starts a new one, calling
pollagain.
Therefore, returning fewer records in each poll call would only slow down temporarily the queue getting filled up.
That said, if we were to also reduce max.queue.size to 1024, it would force Debezium to cross the network for every call to poll. Debezium would have to reach out to MySQL to read more records to satisfy every poll; that would definitively have an impact. However, with the default Kafka Producer settings, it is most likely that one fetch from MySQL would provide many more records than they fit in a single produce request, keeping the Kafka producing phase as the overall bottleneck end to end.
In any case, we do not want to solve the offset commit errors problem by reducing the overall system performance. That would just open the door for other issues.
Limiting the outstanding message queue
Since the root of the problem is how many records are accumulated in the outstanding message queue, one might think that limiting this queue should be the primary solution to the problem. Unfortunately, there is no setting to limit the size of this queue, and the implementation used (IdentityHashMap) is not bound either.
However, if we look at the graph for the source-record-active-count-max metric again, we might notice that the number of active records eventually hit the ceiling and didn’t keep growing.
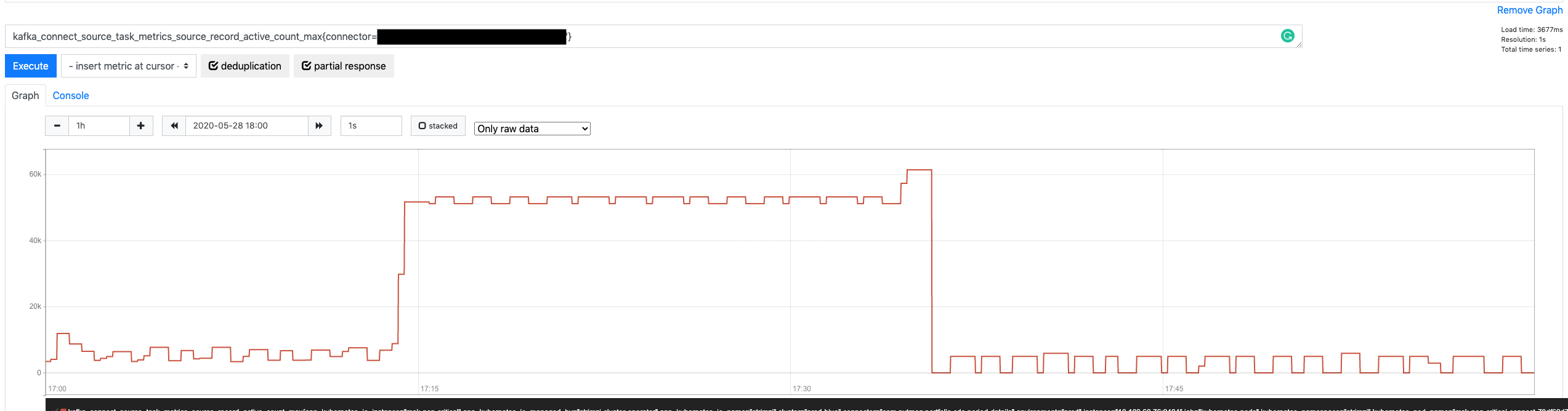
Doesn’t that mean that it is effectively bound? Yes, but not 🙂
It is bound in the sense that there is something that prevents it from growing ad infinitum, but that is more of a happy coincidence that a proper mechanism. What is happening is this:
- Records returned by
pollareputon the outstanding message queue. - Those same records are passed, one by one, to
KafkaProducer‘ssendmethod. - The
sendmethod places them in its internal queue and returns immediately. - If the
KafkaProducerqueue is already filled up,senddoesn’t return; instead, t blocks until there is space in the queue.
That is precisely why the outstanding queue doesn’t grow any further. It is not because it is implicitly limited; it is because the SourceWorkerTask blocks calling send once the KafkaProducer queue is filled up. When that happens, it can’t call poll anymore, and it does not add more records into the outstanding queue.
Another metric can confirm this assumption: KafkaProducer metric for available bytes in its internal queue (buffer-bytes-available)
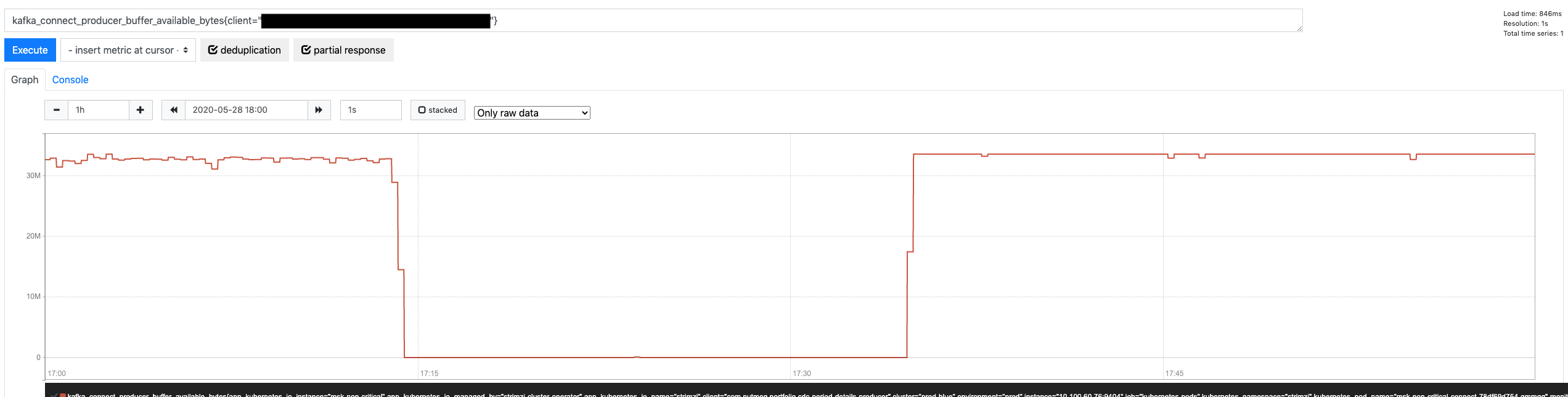
Therefore, we could significantly reduce the size of the outstanding message queue if we reduce the size of the KafkaProducer internal queue, blocking earlier and stopping the SourceWorkerTask from polling more records. The KafkaProducer buffer.memory property does precisely that (defaults to 32 MB). If we reduce its size 50%, it would indirectly cause a similar reduction in the outstanding message queue.
Is this the best strategy, though? While it is the most effective to attack the heart of the problem (the outstanding message queue growing uncontrolled), it is not exempt from problems:
- While there is a relationship between the
KafkaProducerinternal buffer and the outstanding message queue, they are not 100% correlated. TheKafkaProducerbuffer is measured in bytes, while the queue is in number of records. Therefore, their relationship is determined by the size of the consumed records. Depending on the nature of the table, those records could be either fixed in size or vary wildly (e.g., JSON columns) - For a more fine-grained tuning of the outstanding queue size (beyond reducing it 50%), the
buffer.memorywould again have to take an average of the record size into account.
All in all, it is definitively something to consider, but not the first option.
Unlocking more throughput in the Kafka Producer
I started the previous post with a bold statement:
Intuitively, one might think that Kafka will be able to absorb those changes faster than an RDS MySQL database since only one of those two systems have been designed for big data (and it’s not MySQL)
If that is the case, why is the outstanding message queue growing? Admittedly, the queue should never fill up or do it in reasonably at least. Well, the default settings for KafkaProducer optimize sending records to multiple topic/partitions across different brokers at the same time (i.e., applications writing to various topics with multiple partitions each), with multiple concurrent requests (up to 5 by default).
However, for a Debezium connector, we usually:
- Produce to one single topic at a time (especially if the connector is ingesting a table with a lot of traffic)
- Produce to topics with one single partition (to guarantee strict order based on the original’s table activity in the binlog)
- By design, limit in-flight requests to 1 (again, for ordering reasons)
Therefore, we have a completely different scenario where the KafkaProducer default settings result in really poor performance. As we saw in the previous post, we are sending around 25 records per request. Compare to the 8192 records that can pile up in its internal queue and think how many network roundtrips we need to send all of those records.
The first solution to attempt here is to configure the KafkaProducer to unlock Kafka’s performance. The good news is we don’t have to do anything too complicated. Only 25 records make it to every request because every batch is, by default, limited to 16384 (see batch.size property). What happens if we were to apply an x20 factor to this property?
- Every network roundtrip would carry x20 more records (500)
- Records would be acknowledged faster and removed from the outstanding message queue
- By the time a commit offset kicked in, there would be fewer outstanding records, AND the
KafkaProducerwould be able to deliver x20 faster whatever records were pending, within the default 5-sec timeout
Since Kafka Connect 2.3 implemented the option for connector level configurations for KafkaProducer, it is possible to use them in two steps:
- Enable them in your Kafka Connect deployment (https://kafka.apache.org/24/documentation.html#connectconfigs):
connector.client.config.override.policy = all - Configure the producer settings in the connector configuration using the
producer.overrideprefix:producer.override.batch.size = 327680
Increasing batch.size: the aftermath
What is the effect of this config change? Very significant. Let’s start with the obvious: more records per request.

As a result of unlocking more throughput per request, the KafkaProducer in-memory buffer isn’t filling up anymore.

That looks all good, but how is more throughput affecting the Connector? Is it fixing anything there? Let’s look at the number of outstanding messages.
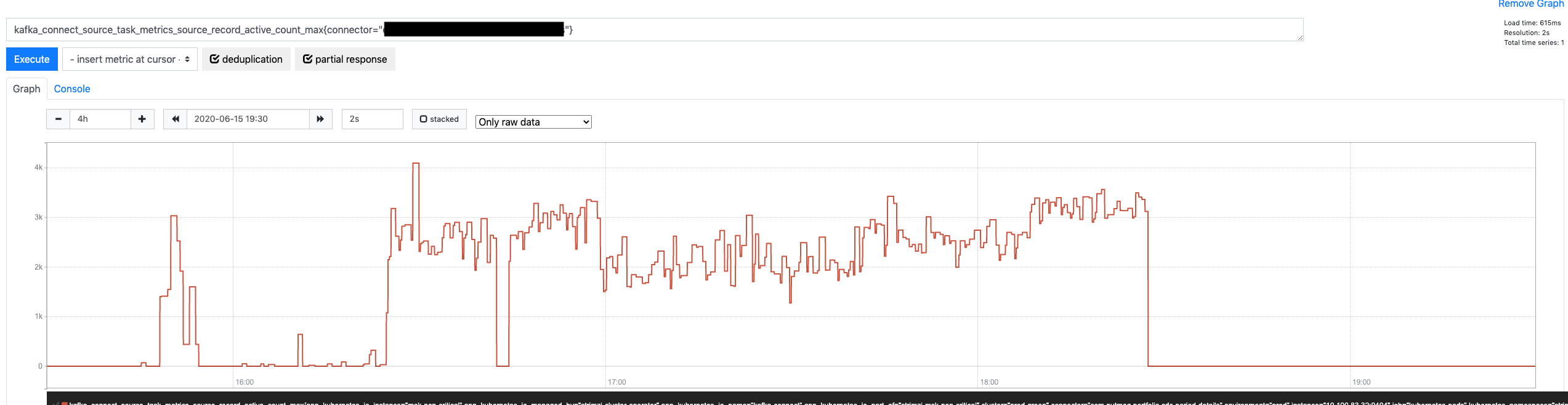
Very promising. On average, the queue is approximately 20x smaller (from peaking at around 60,000 pending messages down to 2,000 – 3,000). Admittedly, this is going to help a lot with the commit offset errors since fewer pending records mean more chances to empty the queue within the offset timeout, but is it enough? Let’s look.

Perfect! Zero errors when committing offsets while the Connector is going through a maximum load period. What is even better, there is a massive margin before committing offsets would take long enough to cause an error. We just need to look at their maximum latency.

Peaking at 60 ms per request is quite good!
Conclusion
While controlling Debezium flow and restricting how large the outstanding message queue could grow (albeit indirectly) were promising strategies, going back to the basics was the best strategy.
Kafka is designed to be faster and more available than any relational database in the market (with similar hardware). That is a bold statement, but a safe one: Kafka does not do any of the great things that make relational databases so useful. It is a more straightforward system that does one thing well: ingest data at maximum speed. With that in mind, it was a matter of tweaking the right config settings to unlock its power.
That said, be aware of any modifications that you do to Kafka settings in either the client or the server-side. As it usually happens with complex, distributed systems, there might be unexpected side effects. As a general rule, as much as possible, aim to test any change in controlled environments before rolling out to production.