In this post, we discuss common errors when committing offsets for connectors under load and how we can assess where the problem is, looking at Kafka Connect logs and metrics.
The Context
As part of its strategy to move into an Event-Driven Architecture, Nutmeg uses heavily Kafka Connect and Debezium to capture changes in data stored on various databases, mostly coming from legacy services. That has proven very effective to kick-start EDA systems without costly up-front investment on those legacy services.
Some of these data changes come from batch-oriented services that will kick in once a day and write heavily into the database at maximum capacity (quite frequently limited only by the EBS volume bandwidth). That, in turn, creates a considerable backlog of changes from the Debezium connector to ingest and publish to Kafka.
Intuitively, one might think that Kafka will be able to absorb those changes faster than an RDS MySQL database since only one of those two systems have been designed for big data (and it’s not MySQL). However, distributed systems are complicated beasts, and the unexpected should be, always, expected.
The Error
Every day, when one of those batch-oriented, heavy writers, was hammering the MySQL database, we would eventually get log entries coming from the connectors like this:
INFO WorkerSourceTask{id=my-connector-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask) [pool-16-thread-1]
INFO WorkerSourceTask{id=my-connector-0} flushing 48437 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask) [pool-16-thread-1]
ERROR WorkerSourceTask{id=my-connector-0} Failed to flush, timed out while waiting for producer to flush outstanding 31120 messages (org.apache.kafka.connect.runtime.WorkerSourceTask) [pool-16-thread-1]
ERROR WorkerSourceTask{id=my-connector-0} Failed to commit offsets (org.apache.kafka.connect.runtime.SourceTaskOffsetCommitter) [pool-16-thread-1]Without failure, a significant increase in the number of capture data changes going through the connectors would result in this type of errors. It seemed counterintuitive, though. Kafka is the fastest system here, and the MySQL database server should be the bottleneck; surely, Kafka Connect would be able to commit its offsets under the default timeout (5 seconds by default, see offset.flush.timeout.ms documentation). What was going on?
Looking Under the Hood
Before knowing why the process was failing, we need to look under the hood to understand what is happening. What does Kafka Connect do? A picture is worth a thousand words:

OK, maybe this does not entirely settle it, let’s look at it step by step:
- A Debezium Connector starts (with
task.max=1), resulting in oneWorkerTaskrunning on a Connect Worker. - This
WorkerTaskspins out aWorkerSourceTask(Debezium is a source connector) and callsexecuteon it. - The
executemethod is, basically, a bigwhileloop that runs indefinitely, unless the task state changes tostoporpaused. - In every iteration of the loop, the
WorkerSourceTaskpolls manySourceRecordinstances provided by the source connector plugin (Debezium in this case). - Those
SourceRecordare stored in a sort of outstanding messages queue, before being provided to aKafkaProducerinstance. - Every
SourceRecordis thensendusing theKafkaProducer. If you know howKafkaProducerinstances work, they don’t send the record over the network whensendreturns. - The record is sent eventually. When it gets acknowledged by the Kafka cluster, a callback is involved, which will
removethe acknowledged record from the pending queue. - Finally, coming from a different thread, every
offset.flush.interval.ms(by default, 60 seconds) theWorkerSourceTaskgets itscommitOffsetsmethod invoked, which triggers the process that results in the errors seeing the previous section.
Simple, right? Well, maybe not, but hopefully clear enough.
One key point here is that the commit process waits until the outstanding messages queue is empty to proceed. It makes sense, it wants to know what records have been successfully produced to commit their offsets, or whatever reference it is used (e.g., GTID, binlog position).
The Hypothesis
Let’s throw a hypothesis for what might be happening here:
Since committing offsets waits until the outstanding message queue is empty, if acknowledging all of them takes anywhere close to the commit offset timeout (5 sec by default), the commit process will fail. We see these errors because the large number of outstanding messages (48437 in the example) take too long to be published successfully
That sounds reasonable, but can we validate it? And can we do something about it afterward? Let’s see
Validating The Hypothesis
Let’s start by determining if the metrics confirm the errors that we see.
Are offset commits really failing?
Kafka Connect has metrics for everything, including commit offsets failing. That metric is offset-commit-failure-percentage:

Unsurprisingly, the metric raises when commit offset failures are reported in the logs.
Are outstanding messages growing?
Next, we should have metrics confirming that the outstanding message queue grows almost unbounded when the connector is under heavy traffic. That metric is source-record-active-count-max (there is also an average version):

There it is, an exact correlation between the outstanding message queue getting out of hand and commit offsets failing.
Why can’t Kafka keep up?
One might think: why isn’t Kafka keeping up with delivering records fast enough, so the outstanding message queue doesn’t go so large? Well, there are multiple pieces involved in this part of the process:
- The
KafkaProducerthat Connect uses to publish the records to Kafka. - The network between the machine running the Kafka worker (K8S node in this case) and the destination Kafka cluster.
- The Kafka cluster itself, potentially multiple brokers, if there is any replication involved (which it almost always is).
If we start with the KafkaProducer, it is important to notice that it uses a relatively standard configuration. These settings are published when the producer is created (upon task creation). If you have given a specific name to your producer’s client.id, you would see an entry like this in your logs (with many more settings, these below are just the most relevant subset):
INFO ProducerConfig values:
acks = all
batch.size = 16384
buffer.memory = 33554432
client.id = my-connector-producer
linger.ms = 0
max.block.ms = 9223372036854775807
max.in.flight.requests.per.connection = 1
max.request.size = 1048576From these settings, we can confirm a few things:
- Requests will need to wait until the record has been replicated before being acknowledged, which would increase the overall request latency.
- Whatever the number of records awaiting is, a request will only contain up to 16,384 (16K) of records. If every record took 1KB, it would only accommodate 16 records in each network roundtrip.
- The producer will only send one request at a time. That guarantees order but decreases throughput.
- Every request can be up to 1MB.
What is the point of having requests up to 1MB if a batch can only be 16KB? The KafkaProducer documentation answers that question:
Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent.
However, this connector is producing to a topic with 1 partition only, meaning the KafkaProducer will not take advantage of the ability to place multiple batches in one single request. Another metric can confirm if this is true: request-size-avg.
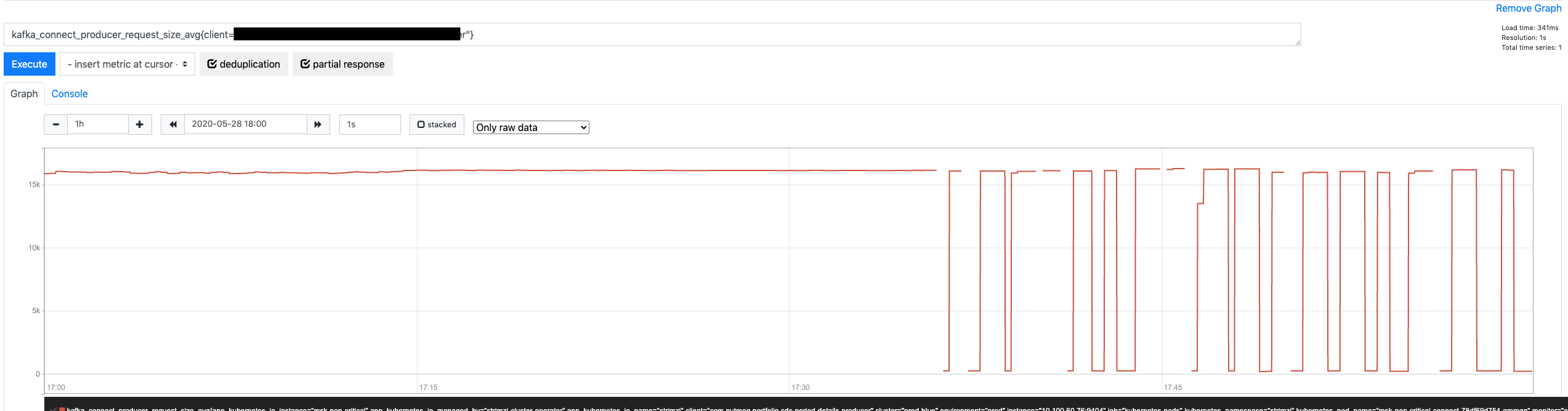
We have this large request size, but we are only using a fraction of it.
Let’s look at this from a different angle. Based on the size of every record, how many records are we packaging in every request to the broker)? Yep, there is another metric for that: records-per-request-avg

Considering that we are packaging a mere 23 records per request, we would need more than 2,000 requests to flush out that queue as it was reported before trying to commit offsets.
Can we publish data faster?
This connector runs on a Kafka Connect worker sitting on top of a K8S node provisioned as an EC2 m5a.2xlarge instance… How much bandwidth does this family have?
According to AWS documentation, up to 10 Gbps.
However, not everybody agrees with this estimation. It seems up to means mostly a burst that won’t last for more than 3 minutes.
Instead, some put the numbers down to a more realistic 2.5 Gbps for a similar family type.
However, whatever the number, where are we up to really? How much extra bandwidth can the connector use? It is a difficult question for a couple of reasons:
- It’s not the only connector/task running in the Connect worker. Other tasks require network too.
- The Connect worker is not the only pod in the K8S node. Other pods will use the network as well.
- There are also availability zones for both K8S nodes and Kafka brokers, which would have to be taken into account.
However, if we ignore all of this just for one second and we look at how much bandwidth the Connect workers are using (any of them), we can see that none of them are above a quite modest 35 MB/s.

That gives us a lot of extra bandwidth until saturating those 2.5 Gbps (i.e., 320 MB/s) for the family type. Yes, the network is shared with other pods in the K8S node, but few of them will be as network-intensive as Kafka Connect.
Can we control the flow at the source?
One could argue that, if Debezium weren’t floading the connector with MySQL data changes, none of this would matter. That is partly true, but not the cause of the problem since the SourceWorkerTask polls records from DBZ whenever it wants.
Debezium has metrics that confirm whether it has records that could provide to the SourceWorkerTask but they haven’t been requested yet: QueueRemainingCapacity

This metric tells us that Debezium puts SourceRecord instances to the internal queue faster than the SourceWorkerTask is polling them. Eventually, the DBZ queue gets full; when this happens, DBZ doesn’t read more binlog entries from the MySQL database until the queue has some capacity.
Also, DBZ delivers up to max.batch.size (defaults to 2,048) records in every poll request. Since the internal queue is permanently filled up during the period where offset commits fail, it is reasonable to think that every poll will return 2K records, adding a huge extra burden to the list of outstanding messages. Yet another Connect metric (batch-size-avg) confirms this:

Conclusion
After going through all of these graphs and detailed explanations, a few things seem pretty clear:
- MySQL/Debezium combo is providing more data change records that Connect / Kafka can ingest.
- The connector is building up a large, almost unbounded list of pending messages. That is the result of its greediness:
polling records from the connector constantly, even if the previous requests haven’t been acknowledged yet. - Eventually, an offset commit request draws a line in the sand and expects this pending list to be empty. By the time that happens, the list is just too big.
- The list grows unbounded because the
KafkaProduceris not optimized for throughput. It is carrying just an avg of 23 records per network roundtrip.
The solution? You’ll have to wait for the next post to find out!

This is a great article. Thanks.
Fantastic write-up.
This is just an awesome explanation. Thanks Javier.
Great article, and nice to find you again after all these years 🙂